

Sự bùng nổ của trí tuệ nhân tạo (AI) trong vài năm trở lại đây đã trở thành cơn sốt mà NVIDIA là cái tên được nhắc đến nhiều nhất. Việc gần như là nhà cung cấp chip tăng tốc xử lý AI ( AI Accelerator) duy nhất trên thị trường khiến hãng này nhanh chóng đứng trong top những công ty có giá trị vốn hoá lớn nhất hành tinh. Tuy nhiên điều đó cũng đồng nghĩa với việc năng lực xử lý AI của cả thế giới đang bị “nghẽn”, hay nói khác đi là mất tính đa dạng và cũng là cạnh tranh, khi hầu hết chúng ta không có lựa chọn nào khác ngoài những con chip của NVIDIA.
Dĩ nhiên không ai muốn phải chịu lệ thuộc vào một cái tên duy nhất, đồng thời cũng không ai muốn NVIDIA ôm trọn nguyên “cái bánh kem” AI này. Một trong số những cái tên “không muốn” ấy là Intel, nhưng để có thể thực sự “giành phần” được không phải là chuyện đơn giản một sớm một chiều. Trong những năm tháng qua, quân bài mà Intel chuẩn bị rồi dùng tới trong hôm nay là sản phẩm có nhiều điểm hết sức đặc biệt – Gaudi từ Habana Labs.

Trước khi đi vào chi tiết Gaudi lẫn Habana, chúng ta hãy điểm qua một chút “thị trường” chip AI hiện nay. Có thể nói nghiên cứu chip xử lý AI không phải là thứ vừa xảy ra mới đây mà đã có lịch sử từ những năm cuối thập niên 80 của thế kỷ trước. Dù vậy các thuật toán AI lúc ấy tương đối còn sơ khai và vì thế những phần cứng để đáp ứng cho các thuật toán trên cũng khá nguyên sơ. Phần lớn chúng được ứng dụng để nhận diện văn bản con chữ từ các ảnh chụp. Loại ngôn ngữ mà chúng “hiểu được” thực tế bị giới hạn bởi mindset của lập trình viên lẫn kích thước tập dữ liệu, chủ yếu là tiếng Anh.
Tới sau này, khi tốc độ xử lý của các vi xử lý – nhất là CPU – ngày càng tăng cao, đặc biệt khi các tập lệnh SIMD (Single Instruction, Multiple Data) xuất hiện trên những con chip trên ngày càng phổ biến hơn, chúng trở thành một lựa chọn hợp lý cho các tác vụ AI. Tuy vậy CPU là 1 thiết kế mang tính đa nhiệm vụ (general purpose), nó vốn không được dành riêng cho bất kỳ tác vụ cụ thể nào. Do đó về cơ bản CPU vẫn có thể xử lý AI, nhưng nhìn chung tổng thể thì nó vẫn chưa đủ nhanh để xử lý những khối lượng công việc nặng nề hơn, đặc biệt là khi tập dữ liệu ngày càng phình to ra từ khi Internet trở nên phổ biến.

Siêu máy tính EOS của NVIDIA được tạo ra từ 10.752 GPU Hopper H100
May thay, GPU với các đặc trưng tính toán song song hàng loạt số lượng lớn (nhân xử lý đơn giản hơn CPU nhưng lại có rất nhiều nhân), “vô tình” lại trở nên rất phù hợp cho tính toán AI, nhất là machine learning, deep learning, AI training… Trên thực tế, chính đặc trưng này của GPU cũng là nguyên nhân mà nó rất được chuộng để “đào” tiền ảo, vì cấu trúc có hàng ngàn nhân xử lý cho phép chạy hàng loạt hàm hash cùng lúc, từ đó trả về hàng chuỗi giá trị trong một thời gian cực kỳ ngắn.
Để cho tiện so sánh, anh em có thể hình dung CPU là 1 thợ thủ công mỹ nghệ dày dạn kinh nghiệm, có khả làm được rất nhiều công việc khác nhau như đục khoét, hàn cắt, đổ khuôn, mài mòn, đánh bóng… Còn GPU là những công nhân giản đơn, hầu hết chỉ làm được 1-2 công việc, không thể đa năng như thợ thủ công trên. Thoạt nghe anh em sẽ nghĩ thợ thủ công “chất lượng” hơn đám công nhân phải không? Điều đó đúng nếu người ta chỉ yêu cầu 2 bên cùng làm ra 1 sản phẩm hoặc sửa một lỗi nào đó trong sản phẩm trên – lúc này tay thợ thủ công có thể làm hết từ A-Z còn đám công nhân chỉ biết đứng nhìn vì không ai hiểu rõ sản phẩm cả.
Nhân CPU thường mạnh mẽ hơn nhưng ít ỏi, có thể xử lý nhanh những tác vụ cấp kỳ, nhưng chậm chạp khi xử lý hàng loạt dữ liệu
Tuy nhiên mọi thứ sẽ đảo chiều 180 độ nếu yêu cầu được đưa ra là 2 bên phải chạy đua sản lượng vào cuối ngày. Từng công nhân có thể sẽ không biết cách làm ra sản phẩm hoàn chỉnh, nhưng mỗi người chỉ cần thành thục một công đoạn là đủ. Bản thân tay thợ thủ công có thể rành 100% mọi thứ, nhưng suy cho cùng tay thợ cũng chỉ có 2 tay và 2 chân, không thể nào làm hết cả 10 công đoạn cùng một lúc như 10 tay công nhân cả. Và tới cuối ngày, thợ thủ công “thua trắng” về số lượng sản phẩm làm được so với đám công nhân “ít kinh nghiệm”. Đấy chính là vấn đề của CPU vs. GPU – khi xử lý hàng loạt dữ liệu số lượng lớn, CPU sẽ bị “đuối sức” trước GPU.

Thực tế mà nói, FPGA (Field Programmable Gate Array – nôm na là mạch IC có thể lập trình lại theo ý khách hàng) là loại chip đầu tiên được dùng để phát triển AI. FPGA có chi phí khá đắt đỏ và năng lực xử lý tuỳ thuộc vào số lượng mạch logic, loại mạch logic mà sản phẩm đó có. Do đó việc dùng FPGA để tính toán AI không thuần tuý như một con chip hoàn chỉnh. Trong đa số trường hợp, FPGA thường được dùng là “mẫu thử nghiệm” (prototype) để đánh giá một thiết kế chip sẽ vận hành ra sao trước khi nó được đưa vô sản xuất hàng loạt. Phần lớn những con chip chúng ta đang dùng là bản hoàn thiện và không thể lập trình lại được.
Do đặc trưng như thế, FPGA cho tới nay vẫn tiếp tục được sử dụng để nghiên cứu AI. Hiện nay 2 hãng FPGA lớn nhất thế giới là Xilinx và Altera đều đã được AMD lẫn Intel mua lại. Không khó để nhận ra rằng các công ty này sẽ tận dụng lợi thế “sân nhà” để thiết kế ra những sản phẩm AI chuyên dụng của mình.


FPGA là công cụ rất tốt để lập trình AI nhưng chi phí đắt đỏ và khó trang bị rộng rãi
Và đó là một phần của câu chuyện Gaudi mà nội dung bài viết này đề cập tới. Nói ngắn gọn, Gaudi là 1 sản phẩm vi mạch chuyên dụng (ASIC – Application-Specific Integrated Circuit) được thiết kế chỉ để tính toán AI và duy nhất AI. Nó khác với các chip GPU của AMD hay NVIDIA ở chỗ chúng là GPGPU (General Purpose Graphics Processing Unit). Về mặt “quy mô” công việc mà nói, GPU hiện nay đảm nhận nhiều vai trò hơn xưa kia. Ngoài việc hiện hình, xử lý đồ hoạ, GPU ngày nay còn hỗ trợ decode video, xử lý hậu kỳ phim ảnh, hỗ trợ tính toán siêu máy tính, “đào” coin… Nói theo kiểu nào đấy thì GPU hiện tại “giống” CPU hơn mục đích ASIC ban đầu (chỉ đơn giản để tính toán đồ hoạ 2D/3D).
Cũng do phải ôm đồm quá nhiều việc như thế, GPU dần mất đi tính chuyên môn của mình. Thiết kế GPU hiện nay phải chứa quá nhiều thành phần khác nhau, từ các nhân đồ hoạ phổ thông cho tới các nhân điện toán cao cấp 64-bit, rồi media encoder/decoder, rồi tới các nhân tensor cho AI. Một thiết kế như thế khiến cho lượng silicon cần bỏ ra cho cả GPU là quá nhiều, nhưng chỉ để xử lý AI thì không đáng kể. Ở góc độ nào có thể xem là “thừa thãi” vì khi xử lý AI thì những thành phần không liên quan sẽ không khai thác được.
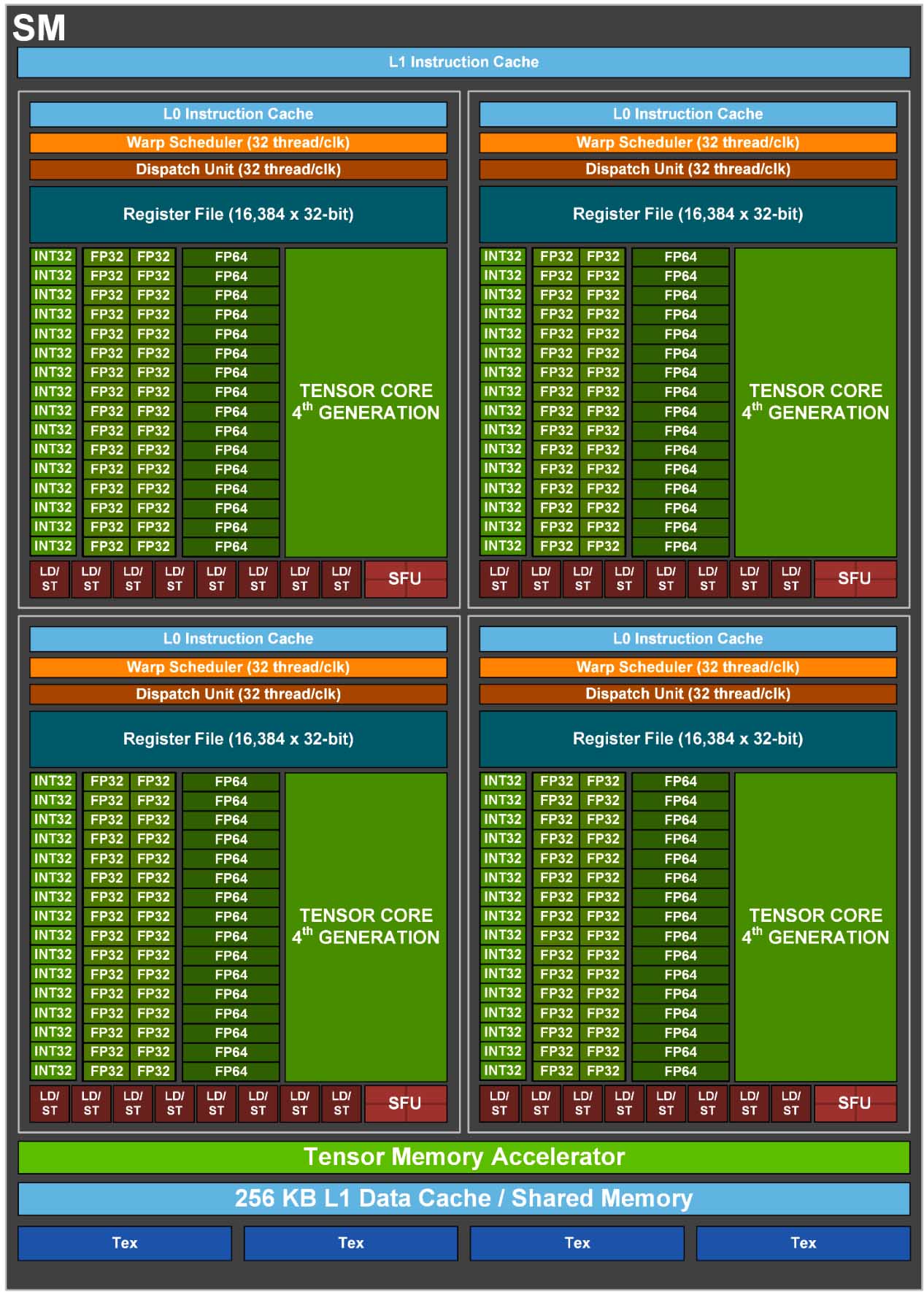
Cấu trúc 1/144 SM của H100 có quá nhiều thành phần chức năng dẫn tới việc không khai thác được toàn bộ cùng lúc
Đây cũng là một trong các nguyên nhân một số hãng công nghệ như Amazon, Microsoft hay Google chuyển qua sử dụng chip AI của riêng mình (ngoài lý do tránh lệ thuộc vô NVIDIA). Vì thiết kế ASIC thì sẽ tận dụng được tối đa lượng silicon bỏ ra để phục vụ riêng AI chứ không bị “tạp nham” như những con chip đa nhiệm vụ. Vì vậy Gaudi, Gaudi 2 và 3 đến từ Habana là những mẫu ASIC như thế.

Một chi tiết cần làm rõ là Gaudi ban đầu không phải sản phẩm của Intel. Habana Labs được thành lập từ 2016 với mục tiêu thiết kế ra những con chip AI hàng đầu. Cho tới 2019 khi sản phẩm đầu tay là Gaudi ra đời thì Habana mới trở thành công ty con của Intel. Gaudi được sản xuất trên tiến trình 16 nm của TSMC nên hoàn toàn không liên quan tới Intel ở thời điểm này.
Giới thiệu Gaudi 1
Nhưng điểm mấu chốt ở đây là Habana không đi theo con đường AI mà AMD hay NVIDIA hay Intel (cho tới trước Gaudi) vẫn đang đi. Cả 3 công ty trên vẫn áp dụng nguyên tắc thiết kế đa nhiệm vụ (CPU/GPU) khi nhắm tới AI. Nên có thể nói công ty nào tiên phong AI trước thì nghiễm nhiên sẽ luôn có lợi thế hơn “kẻ đến sau”. Và Intel lại là kẻ “chân ướt chân ráo” trong cả thiết kế GPU lẫn AI. Nếu “đuổi theo” NVIDIA bằng cách thiết kế GPU cho ngon lành rồi từ con GPU ngon lành mới nhồi nhét nhân Tensor vào cho mạnh về mặt AI thì sẽ mất rất nhiều thời gian (thực tế Intel vẫn áp dụng cả cách này trên dòng sản phẩm GPU Flex, nhưng đó sẽ là một câu chuyện khác) mà không chắc đã có thể theo nổi.

Cấu trúc Gaudi hết sức đơn giản nhưng hiệu quả cao
Vậy nên nếu không có “kỳ biến” thì rất khó có “kỳ tích”. Gaudi của Habana chính là “kỳ biến” này. Vốn bản chất là ASIC, toàn bộ những gì có trên con chip sẽ “toàn tâm toàn ý” dành cho AI. Nên cho dù cả tổng số transistor trên ASIC có thấp hơn GPU thì năng lực AI của nó vẫn không hề kém cạnh. Trở lại câu chuyện như ví dụ trên, lượng công nhân có thể ít hơn lượng thợ nhưng yêu cầu ở đây là chỉ chuyên 1 công việc nhất định.
Về mặt kiến trúc, có thể nói Gaudi khá “đơn giản” khi so sánh với các thiết kế CPU/GPU đa nhiệm vụ khác. Sức mạnh chính của Gaudi nằm 8 nhân Tensor (TPC – Tensor Processor Core) VLIW (Very Long Instruction Word) SIMD và 1 Engine nhân ma trận (GEMM – General Matrix Multiply). Chúng có chung 24 MB bộ nhớ SRAM và được tăng cường thêm 4 chip nhớ HBM2 cho tổng dung lượng RAM tới 32 GB. Khả năng “nói chuyện” với các chip Gaudi hoặc CPU khác trong cùng hệ thống được thông qua 10 cổng Ethernet 100 Gbit và 16 lane PCI Express 4.0. Các nhân TPC hỗ trợ các loại toán tử FP32, BF16, INT32, INT16, INT8, UINT32, UINT16 và UINT8.
Nhưng Gaudi là một sản phẩm tương đối hơi “muộn” khi được sản xuất trên tiến trình 16 nm của TSMC. Chi tiết này có thể “thông cảm” vì Habana tại thời điểm chưa được Intel mua lại chỉ là một công ty nhỏ, khó lòng chen chân với những cái tên sừng sỏ khác trong làng bán dẫn. Sau khu thuộc về Intel, Gaudi 2 mới thực sự là điểm nhấn.

Có thể nói tuy “bị” Intel mua lại, nhưng cái “chất” của Habana vẫn không thay đổi. Gaudi 2 về cơ bản là phiên bản “phóng to” của Gaudi 1 trên nền tảng 7 nm của TSMC. Bộ tăng tốc AI thế hệ 2 này có tới 24 TPC, 2 engine nhân ma trận (MME – Matrix Multiplication Engine). Bộ nhớ chung SRAM tăng lên 48 MB và số chip HBM2e tăng lên 6, cho tổng dung lượng RAM tới 96 GB. Đặc biệt, mỗi con chip Gaudi 2 sẽ có tới 24 cổng Ethernet 100 Gbit, và 21/24 cổng này được dùng để “chat” với 7 con chip Gaudi 2 khác trong 1 hệ thống 8 card (trên Gaudi 1 là 7/10 cổng).

Nói gì thì nói, mọi lý thuyết sẽ là vô nghĩa nếu nó không được thể hiện ra ngoài thực tế. Tại thời điểm ra mắt, Gaudi 2 được Intel xác định cạnh tranh với Ampere A100 của NVIDIA (cùng 7 nm, ra mắt trước 2 năm). Và những con số benchmark ban đầu do chính Habana công bố cho thấy Gaudi 2 hoàn toàn đè bẹp Ampere trên phương diện AI. Lẽ tất nhiên điều này không khó hiểu khi Gaudi 2 là một thiết kế ASIC còn Ampere là một GPGPU.
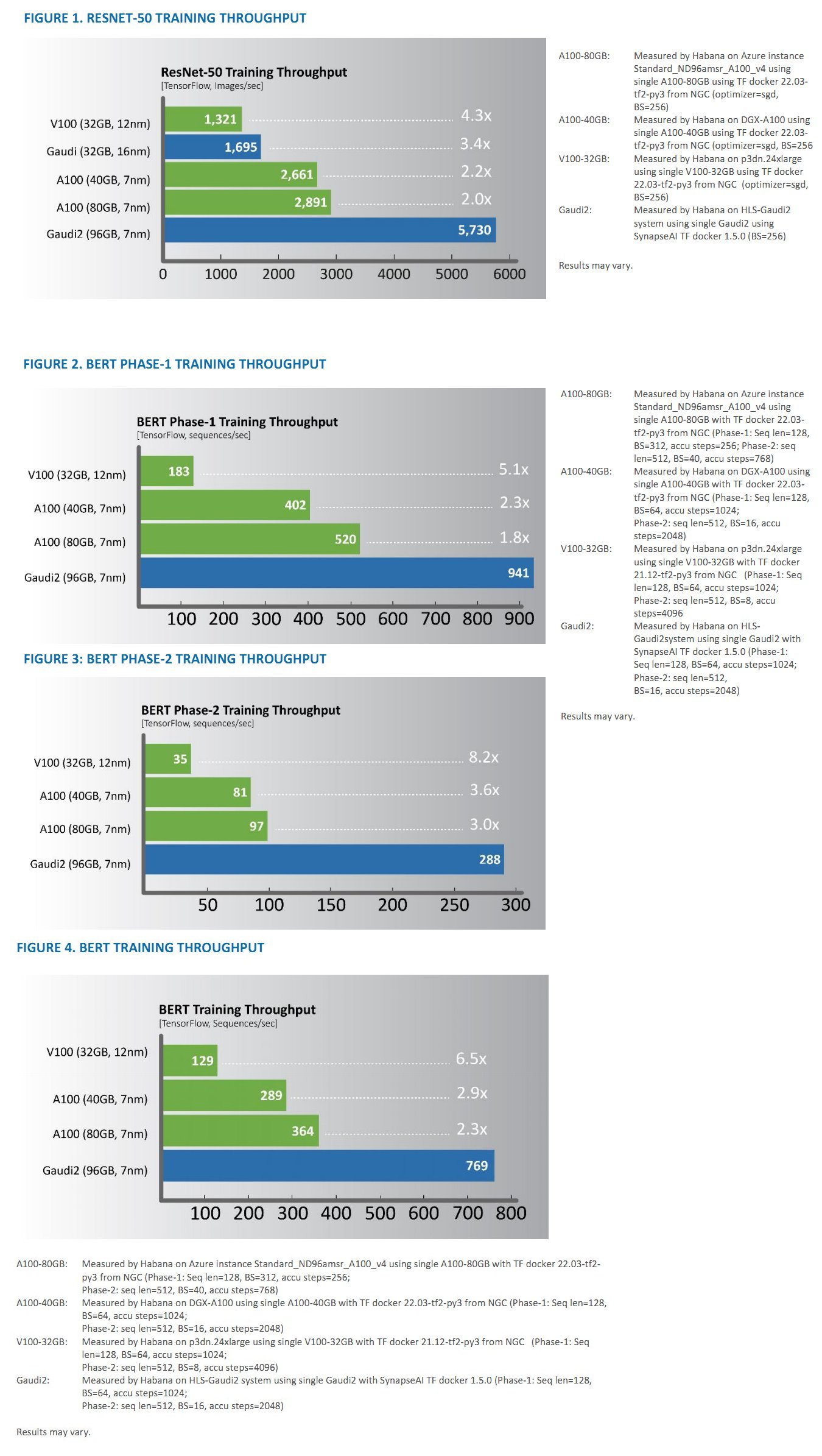
So sánh hiệu năng AI giữa Gaudi 2 và Ampere A100
Có lẽ chính sự xuất hiện đầy bất ngờ này của Gaudi 2 đã khiến NVIDIA “giật mình” nên chỉ vài tháng sau đó, “ông hoàng” AI quyết định ra mắt Hopper H100 để giành lại ngôi vương. Đương nhiên kết quả là H100 chiếm ưu thế tuyệt đối khi được sản xuất trên nền tảng 4 nm của TSMC (phiên bản đặc biệt cho NVIDIA), có số lượng transistor nhiều gần gấp rưỡi A100 (80 vs. 54 tỉ transistor). Dù Habana không tiết lộ Gaudi 2 có bao nhiêu transistor, song với kích thước gần tương đương A100 (cùng 7 nm), có thể ước tính con số cũng không quá khác biệt so với A100.
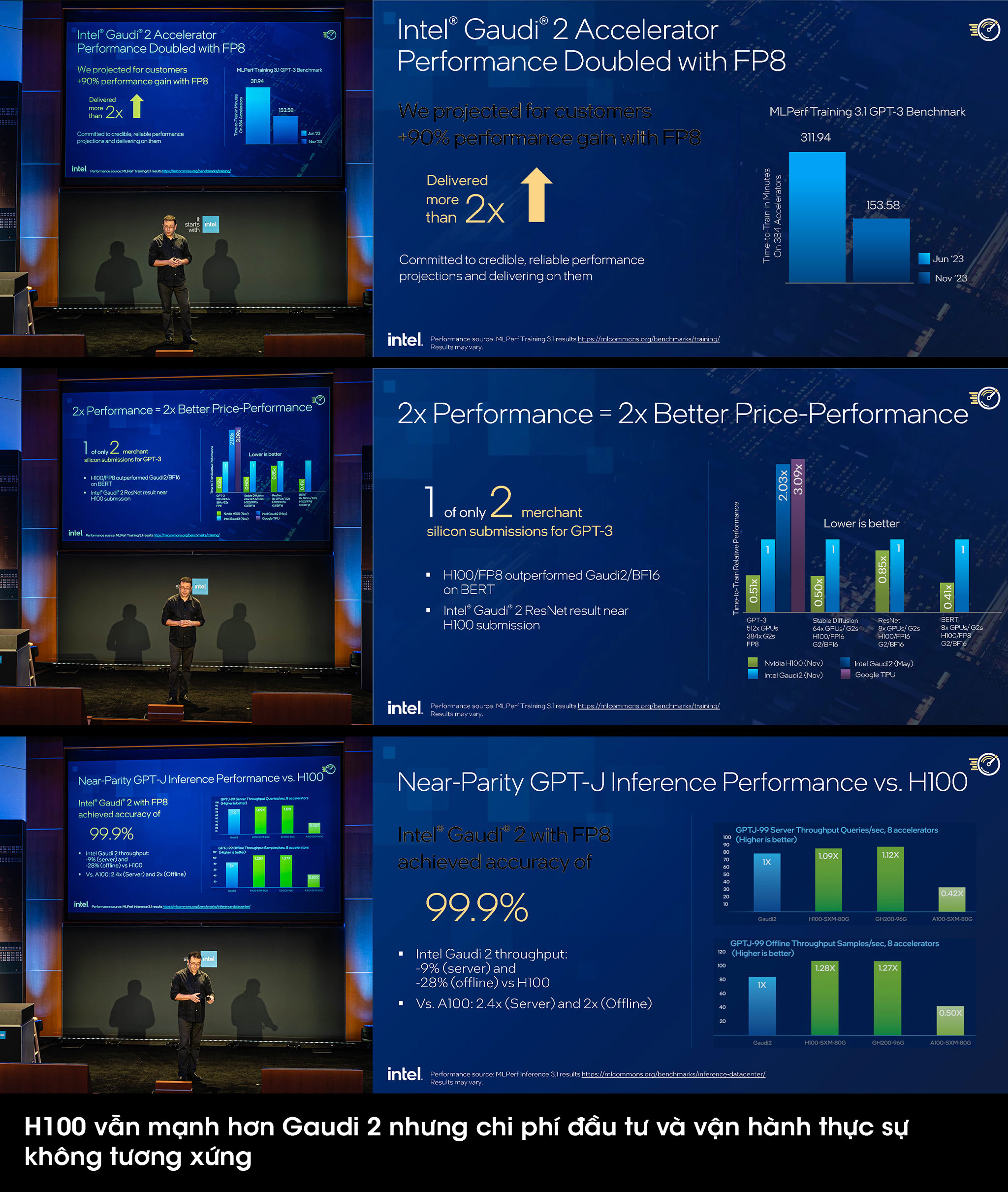
Một điểm hết sức thú vị nữa ở Gaudi 2 là sau lần ra mắt đầu tiên hồi tháng 5/2022, tới tháng 11/2022 (hơn 1 tháng sau khi Hopper ra mắt), Habana lại công bố thêm kết quả benchmark mới trên nền tảng GPT-3. Điểm khác biệt là lần này Gaudi 2 bổ sung thêm toán tử FP8 (trước đó dùng toán tử BF16). Sự thay đổi này mang đến cách biệt về hiệu năng gấp đôi so với trước đó. Tuy rằng vẫn còn khoảng cách khá xa giữa Gaudi 2 và H100, nhưng cần chú ý Gaudi 2 được ra mắt để cạnh tranh với A100 (có giá tương đương), chứ không phải là H100. Intel cũng không bỏ phí dịp để “troll” NVIDIA khi thể hiện những benchmark mà H100 tốt hơn Gaudi 2, nhưng chi phí bỏ ra thực sự không tương xứng. Cặp đôi cùng hạng cân chính xác phải là Gaudi 2 – A100, nếu đem H100 để so sánh thì khá buồn cười.
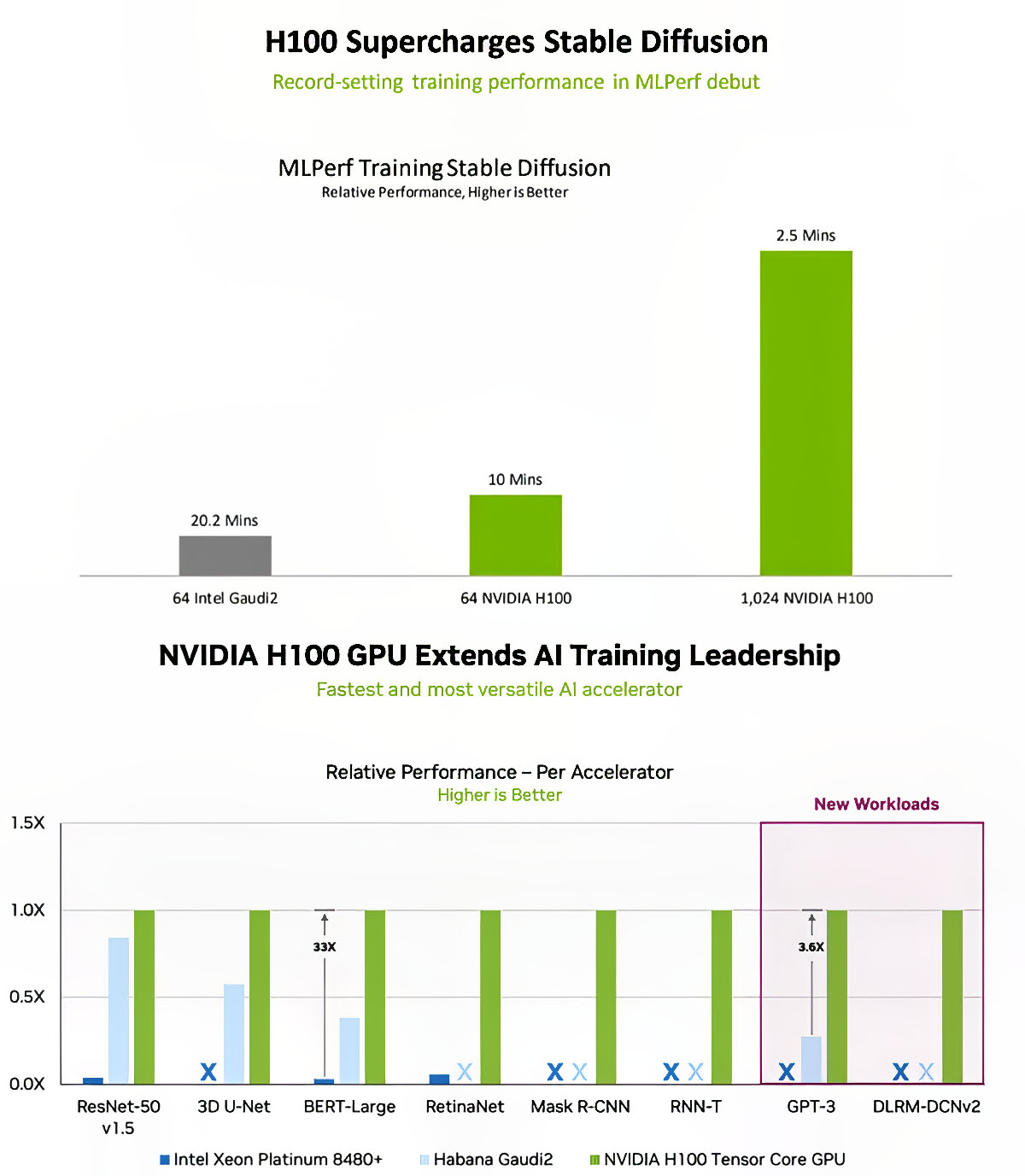
Các so sánh hiệu năng của NVIDIA càng làm nổi bật Gaudi 2 hơn
Bản thân NVIDIA sau màn “trả đũa” khi show-off những benchmark cho thấy H100 mạnh hơn, không ngờ lại “vô tình” thể hiện cho người xem thấy Gaudi 2 có hệ số hiệu năng/giá thành hơn hẳn. Lấy ví dụ với bài test Stable Diffusion, 1 hệ thống 64 chip Gaudi 2 cần hơn 20 phút để huấn luyện, thì hệ thống tương tự với 64 chip H100 mất chỉ có phân nửa thời gian. Nhưng khôi hài ở chỗ hệ thống 1024 chip H100 (nhiều gấp 16 lần) lại hoàn thành mất tới 2.5 phút (chỉ nhanh gấp 4 lần), tỉ lệ tăng không tương xứng và thậm chí có phần bất hợp lý. Bước đi “dìm hàng” đối phương (mà tác dụng ngược) thế này quả thật không thể ngờ tới!

Nhưng để thực sự lật đổ được NVIDIA thì Intel cần phải mạnh hơn. Đó chính là mục tiêu mà Gaudi 3 đang hướng đến. Trên thực tế ngay ở thời điểm đầu tiên ra mắt Gaudi 2, Eitan Medina – COO Habana – đã tiết lộ: “Gaudi 3 sẽ ra mắt sớm thôi. Thực tế nó đang được sản xuất. Đây sẽ là sản phẩm dựa trên công nghệ TSMC 5 nm của chúng tôi”. Còn trong lộ trình ra mắt sản phẩm hồi tháng 3 này, Intel cho hay nó sẽ xuất hiện vào đầu 2024, ngay sau khi công bố dòng chip Xeon Emerald Rapids mới.

Thông số cấu hình Gaudi 3 hiện chưa được tiết lộ, nhưng nếu dựa trên hình ảnh của Intel, có thể thấy Gaudi 3 sử dụng thiết kế 2 chiplet. Số lượng chip nhớ HBM tăng lên 8 chip, năng lực xử lý BF16 tăng lên gấp 4 lần, băng thông mạng tăng gấp 2 lần. Nếu tất cả đều không có gì thay đổi, Gaudi 3 hoàn toàn có thể đè bẹp H100 tại thời điểm ra mắt. Giả sử chuyện này xảy ra, NVIDIA buộc lòng phải ra mắt sớm dòng chip Blackwell được đồn đoán sẽ dựa trên công nghệ 3 nm của TSMC. Vấn đề nằm ở chỗ Blackwell vẫn tiếp tục là một GPGPU, chúng ta cũng không rõ liệu số transistor trên Blackwell sẽ nhiều hơn Hopper bao nhiêu lần. Tuy nhiên thực tế cho thấy là từ 7 nm xuống 4 nm, Hopper chỉ có 80 tỉ transistor chứ không nhiều gấp đôi Ampere ở mức 54 tỉ. Nếu Blackwell cũng tương tự thì dự đoán có khoảng 120 tỉ transistor, còn năng lực tính toán AI giữa Gaudi 3 và Blackwell ra sao chắc sẽ rất hot trong thời gian tới.

Và đây cũng là lúc chúng ta nên đánh giá lại ngôn ngữ thiết kế chip nào phù hợp hơn cho AI – ASIC hay GPGPU? Mình không nói rằng những mẫu GPU của AMD và NVIDIA “yếu đuối”, nhưng bản thân việc phải ôm đồm quá nhiều chức năng đã khiến cho chúng phải phình to quá mức và ở chừng mực nào đó, trở nên kém hiệu quả về mặt tiêu thụ điện năng (do có những thành phần buộc phải bật kể khi không có vai trò gì đáng kể như xử lý AI). Trong khi một thiết kế dành cho siêu máy tính (HPC) lại yêu cầu tới các năng lực tính toán FP64 thì AI lại vốn chẳng cần thứ đấy và ngược lại.

Nếu nhìn kỹ vào cấu trúc sản phẩm dành cho AI của Intel, ta có thể thấy Gaudi chiếm vị trí tối thượng ở trên cùng, trong khi những dòng sản phẩm đa chức năng như GPU/CPU chỉ nắm giữ những vai trò thấp hơn. Đây cũng là nơi mà AMD hay NVIDIA hay những tên tuổi công nghệ khác cần nhìn nhận lại – một thiết kế đa nhiệm vụ dành cho mọi thứ có chắc đã là hiệu quả hơn so với chuyên biệt?
Theo tinhte.vn

